Beberapa pekan lalu saya membaca artikel dari SemiAnalysis mengenai Intel Emerald Rapids. Di dalam artikel tersebut dijelaskan mengenai perubahan yang dibawa oleh Emerald Rapids dari Sapphire Rapids, desain floorplan dan arsitektur keduanya, serta konfigurasi dan biaya dari sisi engineering-nya. Banyak hal yang menarik untuk ditelisik lebih lanjut terkait artikel tersebut sehingga membuat saya menulis artikel ini.

Kilas Singkat: Performa Sapphire Rapids
Sebelum membaca artikel tersebut, saya sudah membaca beberapa pengujian Sapphire Rapids versi server (Xeon Platinum 8490H) dan workstation (Xeon w9-3495X). Berdasarkan hasil uji yang saya baca, prosesor besar terbaru dari Intel tersebut tidak cukup kompetitif bila dibandingkan dengan kompetitor baik EPYC maupun Threadripper.
Berikut adalah sekilas hasil pengujian Phoronix pada Intel Xeon Platinum 8490H menggunakan software high-performance computing (HPC) yaitu GROMACS. GROMACS adalah software komputasi dinamika molekuler yang ditujukan untuk membuat simulasi protein, lemak, dan asam nukleat.
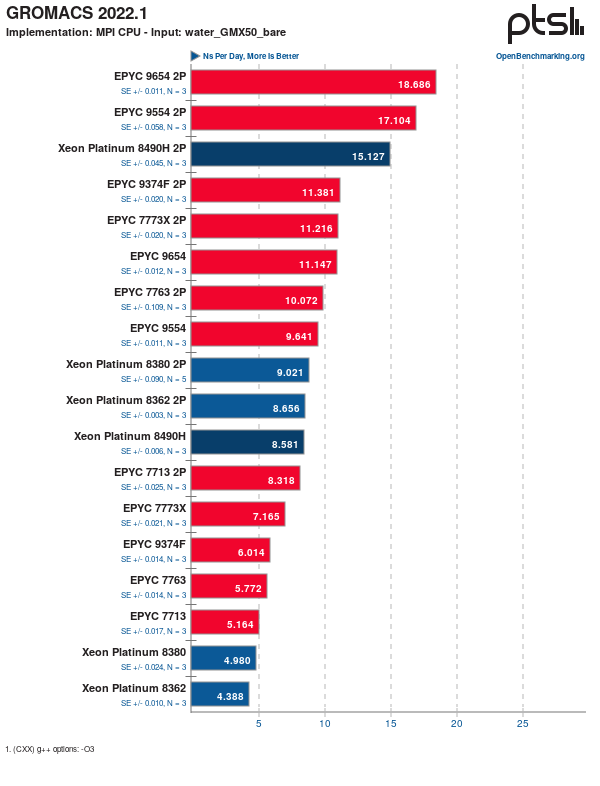
Terlihat pada grafik di atas bahwa Xeon Platinum 8490H signifikan tertinggal dibandingkan dengan EPYC 9654 (AMD Genoa 96-core) dan EPYC 9554 (AMD Genoa 64-core) baik di konfigurasi tunggal maupun prosesor ganda (2P).
Kemudian dari sisi workstation, berikut adalah pengujian Xeon w9-3945X oleh PugetSystem dalam melakukan render menggunakan software grafis 3D yaitu Blender.
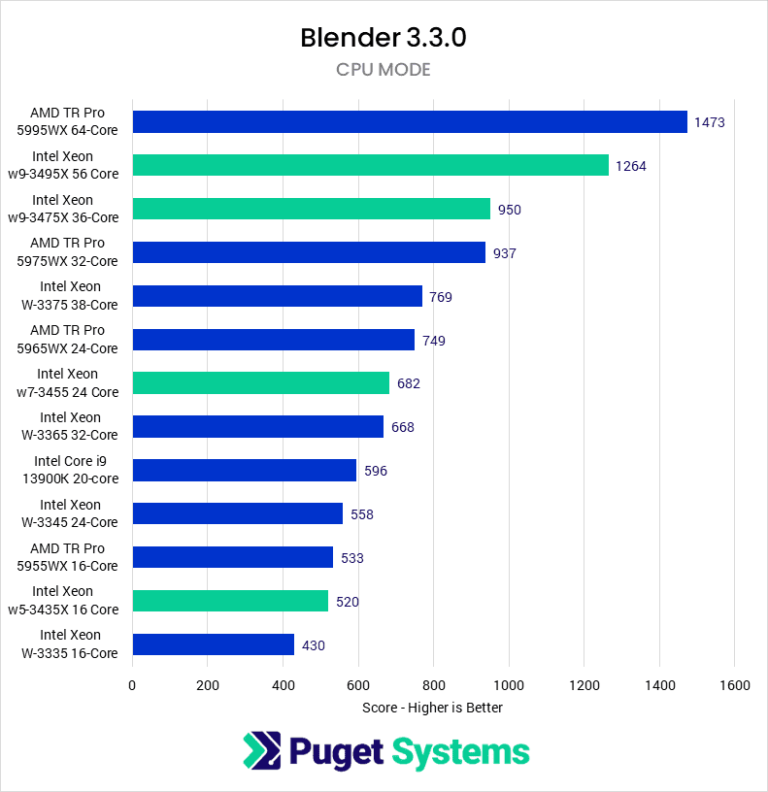
Lagi-lagi secara performa Xeon w9-3945X tertinggal dibandingkan kompetitornya di kelas workstation yaitu Ryzen Threadripper Pro 5995WX. Walau secara jumlah core Xeon w9-3945X lebih sedikit, namun jarak performa ini tidak seharusnya terjadi mengingat mikroarsitektur Golden Cove di Sapphire Rapids relatif lebih baru dibanding Zen 3 pada seri Threadripper 5000WX. Belum lagi ia juga menggunakan memori DDR5 yang memberikan bandwidth lebih besar dibandingkan DDR4 pada seri prosesor AMD tersebut.
Kilas Balik: EPYC Chiplet vs Xeon Monolitik
7 Agustus 2019 mungkin merupakan tanggal paling traumatik bagi eksekutif Intel terutama di bagian Data Center and Artificial Intelligence (DCAI). Di tanggal tersebut, AMD meluncurkan prosesor server mereka yaitu seri EPYC 7002 yang dikenal dengan nama lain: EPYC Rome.
Seri EPYC 7002 hadir dengan spesifikasi hingga 64-core, jumlah core yang masif di masanya. Lini prosesor tersebut juga menghadirkan teknologi chiplet, di mana sejumlah die prosesor digabungkan ke dalam satu package. Chiplet tersebut kemudian dihubungkan satu sama lain melalui IO die sebagai hub dan interkoneksi Infinity Fabrics.

Sebagai perbandingan, seri Intel Xeon Cascade Lake tertinggi saat itu ada di 28-core dengan desain monolitik. Desain monolitik dengan jumlah core sebanyak itu dan fabrikasi yang masih tertinggal di 14 nm menghasilkan ukuran die chip yang sangat besar seperti dapat dilihat pada gambar di bawah.

Desain monolitik meningkatkan kemungkinan die cacat (defect) sehingga mengurangi angka produksi die yang dihasilkan per wafer. Akibatnya, modal produksi per die juga meningkat. Ilustrasi yield die per wafer dapat dilihat pada gambar di bawah.
_-_Version_2_-_EN.png)
Dari sisi performa, Xeon Cascade Lake seri tertinggi yaitu Xeon Platinum 8280 kalah bersaing melawan EPYC 7742 sebagai prosesor EPYC Rome tertinggi. Pada pengujian di software dinamika molekuler seperti NAMD yang populer di lingkungan HPC, Xeon Platinum 8280 bahkan tertinggal 1,5 kali lebih lambat.
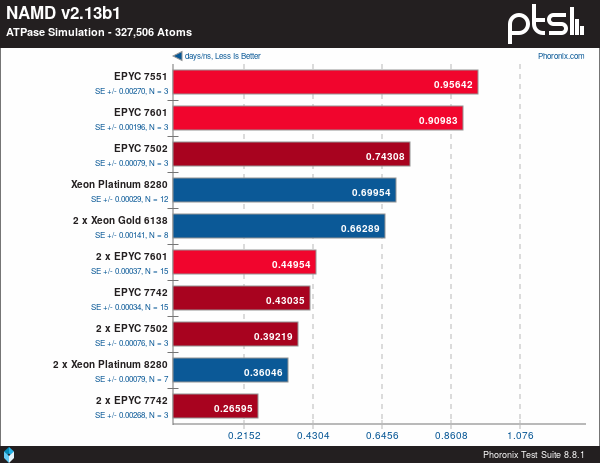
Akibat kesulitan-kesulitan yang terjadi pada fabrikasi 10 nm, Intel terpaksa bertahan di arsitektur 14 nm hingga Xeon Cooper Lake pada 2020 yang juga masih terbatas pada 28-core. Desain monolitik juga membatasi yield dari die yang dihasilkan per wafer bila dibandingkan dengan AMD EPYC yang menggunakan chiplet.
Merancang Sapphire Rapids: Chiplet dan Jumlah Core sebagai Target
Sejak rilisnya EPYC 7002 pada Agustus 2019, Intel praktis tidak memiliki prosesor server yang kompetitif di bidang komputasi (HPC). Ironisnya, masa pandemi lalu adalah masa di mana hampir seluruh enterprise di seluruh dunia memesan server. Hal ini juga yang membuat pendapatan AMD meroket secara signifikan selama 3 tahun terakhir.
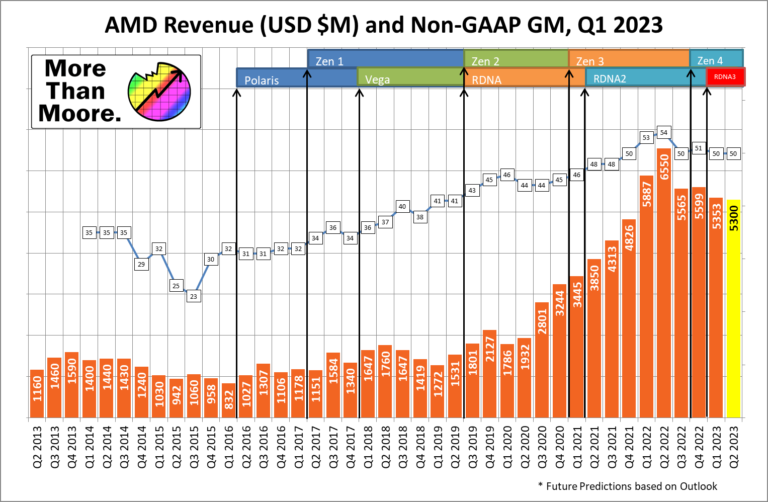
Sebaliknya, Intel mengalami stagnasi pendapatan di rentang waktu yang sama. Di sisi lain, resesi ekonomi 1,5 tahun terakhir memukul Intel lebih dalam bila dibandingkan dengan AMD selaku kompetitor utama di bidang prosesor server.
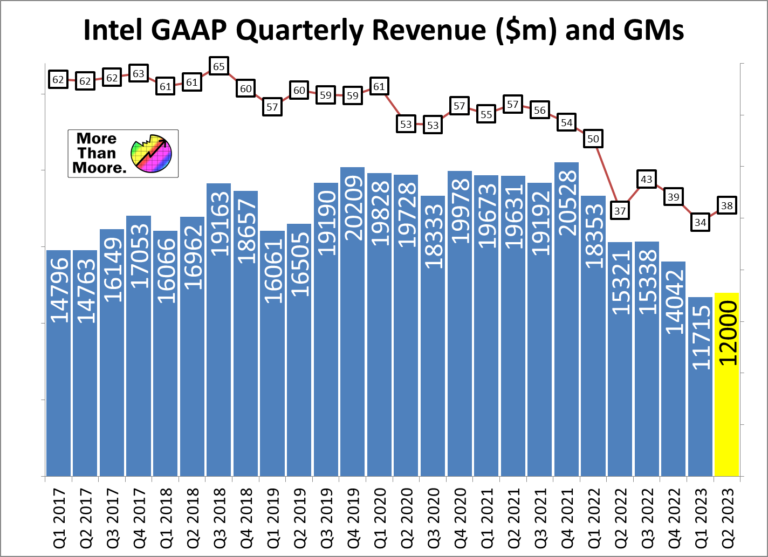
Sebagai usaha untuk mengembalikan kejayaan Xeon, Intel mengumumkan Sapphire Rapids pada Intel Architecture Day 2021. Prosesor yang didesain dengan mikroarsitektur Golden Cove ini menggunakan desain tile yang mirip seperti chiplet pada AMD EPYC.

Desain tile dibuat dengan harapan menghasilkan total luasan die yang lebih besar bila dibandingkan dengan desain monolitik. Luasan die yang lebih besar ditambah pula dengan target desain jumlah core yang lebih tinggi untuk menghadapi kompetitor memaksa Intel untuk menggunakan chiplet demi meningkatkan yield.
| Unit | Xeon Sapphire Rapids | EPYC Milan |
|---|---|---|
| Mikroarsitektur | Golden Cove | Zen 3 |
| Jumlah core maksimal per SKU | 60-core | 64-core |
| L2 cache per core | 2 MB | 0,5 MB |
| L3 cache per core | 1,875 MB | 4 MB |
| Fabrikasi | Intel 7 (10nm SuperFin) | TSMC N7P untuk core GlobalFoundries 14LPP untuk IO die |
Desain Sapphire Rapids: Boros di Interkoneksi, Kurang di Cache
Secara mikroarsitektur, Golden Cove terbukti kompetitif di kategori komputer klien. Implementasi di Intel Core i gen 12 (Alder Lake) menunjukkan bahwa mikroarsitektur ini mampu memberikan performa yang signifikan lebih kencang bila dibandingkan dengan Zen 3 milik kompetitor di masanya.


Namun seperti yang dapat dilihat pada bagian Kilas Balik: Performa Sapphire Rapids di atas, Sapphire Rapids yang menggunakan mikroarsitektur Golden Cove kalah kompetitif dibanding EPYC maupun Ryzen Threadripper berarsitektur Zen 4 dan Zen 3. Hal ini tidak hanya karena faktor jumlah core, namun juga performa per core yang kalah kencang karena konfigurasi cache yang kurang optimal. Berikut adalah tabel perbandingan generasi prosesor dengan ukuran cache-nya masing-masing:
| Unit | Core i gen 12 (Alder Lake) P-core | Xeon Scalable gen 4 & Xeon w-3400 (Sapphire Rapids) | Ryzen 5000 (Raphael) | EPYC 7002 & Ryzen Threadripper Pro 5000WX (Milan/Chagall) |
|---|---|---|---|---|
| Mikroarsitektur | Golden Cove | Golden Cove | Zen 3 | Zen 3 |
| L2 cache per core | 1,25 MB | 2 MB | 0,5 MB | 0,5 MB |
| L3 cache per core | 3 MB (SKU tanpa e-core) 3 MB+, di-share dengan e-core | 1,875 MB | 4 MB | 4 MB |
| Fabrikasi | Intel 7 (10nm SuperFin) | Intel 7 (10nm SuperFin) | TSMC N7P untuk core die GlobalFoundries 12LP untuk IO die | TSMC N7P untuk core die GlobalFoundries 14LPP untuk IO die |
Jumlah cache yang kecil per core ini saya duga karena target jumlah core per chip yang terlalu tinggi. Mengingat chip Sapphire Rapids dibentuk dari 4 chiplet dengan fungsi yang sama dan susunan fisik sedemikian rupa, tiap chiplet harus dapat berkomunikasi dengan chiplet tetangganya melalui antarmuka EMIB (embedded multi-die interconnect bridge).

Berdasarkan perhitungan dari SemiAnalysis, antarmuka EMIB di Sapphire Rapids menghabiskan sekitar 16,2% dari total luasan die. Berikut pada gambar di bawah adalah floorplan dan anotasi Sapphire Rapids revisi awal dan versi retail.
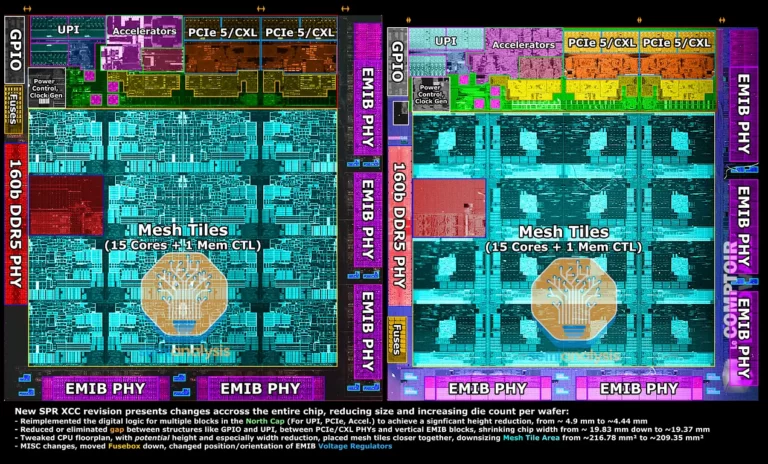
Bandingkan dengan gambar floorplan Zen 3 di bawah yang menggunakan antarmuka Global Memory Interconnect 2 (Infinity Fabric). Luasan die chiplet yang digunakan untuk GMI2 hanya sebesar 6,28%. Sehingga, sisa luasan die dapat digunakan untuk jumlah core yang lebih banyak, desain core yang lebih lebar, maupun ukuran cache yang lebih besar.
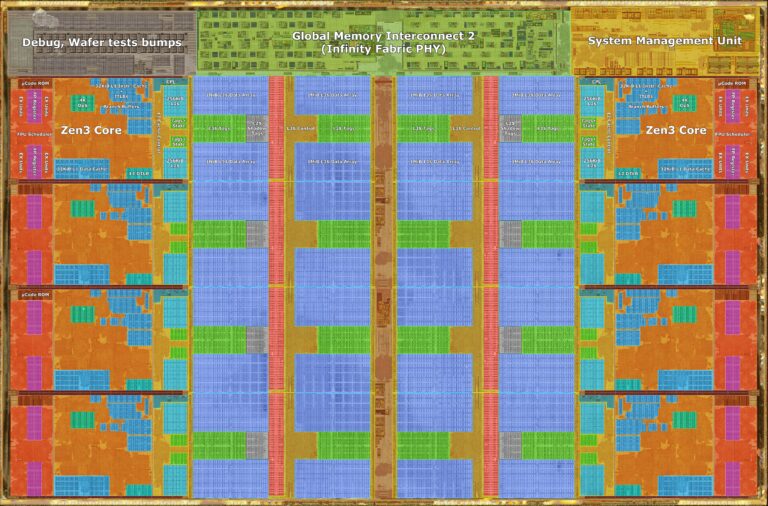
Desain floorplan dan ukuran cache Sapphire Rapids yang suboptimal membuat Intel mendesain ulang lini prosesor enterprise mereka dalam bentuk Emerald Rapids. Desain ulang ini masih menggunakan mikroarsitektur Golden Cove namun dengan beberapa perubahan konfigurasi.
Emerald Rapids dibentuk dari 2 tile saja sehingga luasan antarmuka EMIB per die chiplet dapat dikurangi menjadi 5,8%. Hal tersebut menghasilkan desain baru yang memungkinkan jumlah core yang lebih banyak hingga 66-core dan L3 cache yang lebih besar yaitu 5 MB per core.

Berikut adalah tabel perbandingan luasan die yang digunakan untuk interkoneksi antar chiplet dan besar L3 cache per core:
| Unit | Xeon Scalable gen 4 & Xeon w-3400 (Sapphire Rapids) | Xeon Scalable gen 5 (Emerald Rapids) | EPYC 7002 & Ryzen Threadripper Pro 5000WX (Milan/Chagall) |
|---|---|---|---|
| Persentase die untuk interkoneksi antar chiplet | 16,2% | 5,8% | 6,28% |
| L3 cache per core | 1,875 MB | 5 MB | 4 MB |
Tantangan Desain Chiplet: Mendesain Interkoneksi
Menghadirkan solusi chiplet untuk mengatasi limitasi fabrikasi die monolitik memang merupakan sebuah tantangan tersendiri. AMD sebelumnya belajar dari pengalaman mereka dengan EPYC 7001 (Naples) yang kemudian disempurnakan dengan keberadaan IO die di EPYC 7002 (Rome). IO die menjadi hub untuk mengurangi kebutuhan jalur interkoneksi antar chiplet sehingga kebutuhan luasan die untuk antarmuka interkoneksi menjadi lebih sedikit.
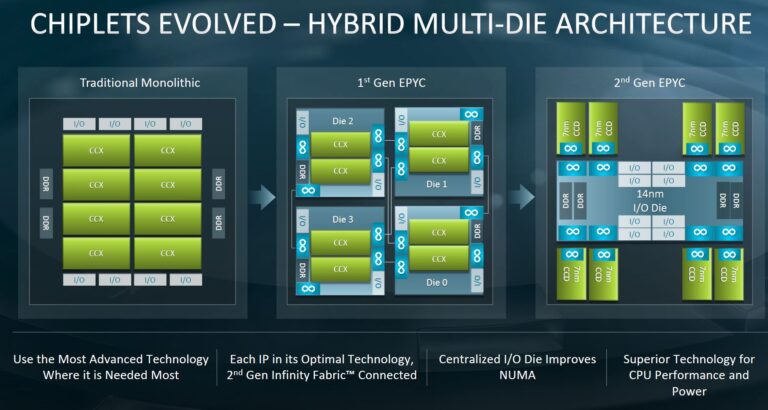
Terlihat pada gambar diagram di atas bahwa pada generasi pertama EPYC, AMD juga mengalami tantangan yang sama dengan Intel Sapphire Rapids. Tanpa adanya hub, seluruh chiplet harus saling terkoneksi satu dengan lainnya sehingga tiap die memerlukan hingga 4 antarmuka Infinity Fabrics.
Ringkasan
Mendesain sebuah chip memang bukan urusan yang mudah. Mulai dari arsitektur, susunan cache, interkoneksi, hingga limitasi fabrikasi. Sapphire Rapids dengan jumlah core yang banyak hadir karena tuntutan dari pasar baik dari bidang high-performance computing (HPC), hyper-converged infrastructure (HCI), dan cloud computing. Limitasi fabrikasi memaksa Intel membuat ukuran die yang lebih kecil untuk meningkatkan yield dan memilih jalan desain chiplet dengan 4 tile per chip.
Desain 4 tile per chip menjadi masalah baru di Sapphire Rapids yaitu luasan die yang digunakan untuk interkoneksi menjadi lebih besar. Akibatnya, luasan die yang tersisa untuk sisi core dan cache menjadi lebih sedikit. Selanjutnya, Intel memilih untuk memperbanyak core dan mengurangi cache pada Sapphire Rapids sehingga mengurangi performa per core dari desain mikroarsitektur Golden Cove.
Seiring dengan berjalannya waktu dan pengembangan di sisi fabrikasi, Intel mendesain ulang Sapphire Rapids menjadi Emerald Rapids yang hanya menggunakan 2 tile. Desain yang lebih baru ini membuat luasan interkoneksi yang lebih kecil sehingga Intel mampu memasukkan cache yang lebih besar. Harapannya, hal ini mampu mendongkrak performa dan membuat Emerald Rapids menjadi lebih kompetitif.
Penutup
Kalau kalian suka dengan artikel ini, kalian bisa dukung melalui Trakteer.